이번엔 Efficient String Matching : An Aid to Bibliographic Search이라는 논문에 대해 리뷰해볼까 합니다.
해당 논문은 유명한 문자열 매칭 알고리즘인 "아호코라식"에 대한 논문입니다.
아호 코라식 알고리즘에 대해 이해하기에 앞서 kmp와 trie 알고리즘에 대해 어느 정도 알고계시면 이해하기 쉽습니다.
KMP
"ABAABC"라는 문자열에 "ABC"라는 단어가 부분 문자열로 존재하는지 체크하는 과정을 단순 반복문을 통하여 진행하게 되면, 맨 앞에 단어부터 해당 형식으로 진행하게 됩니다.
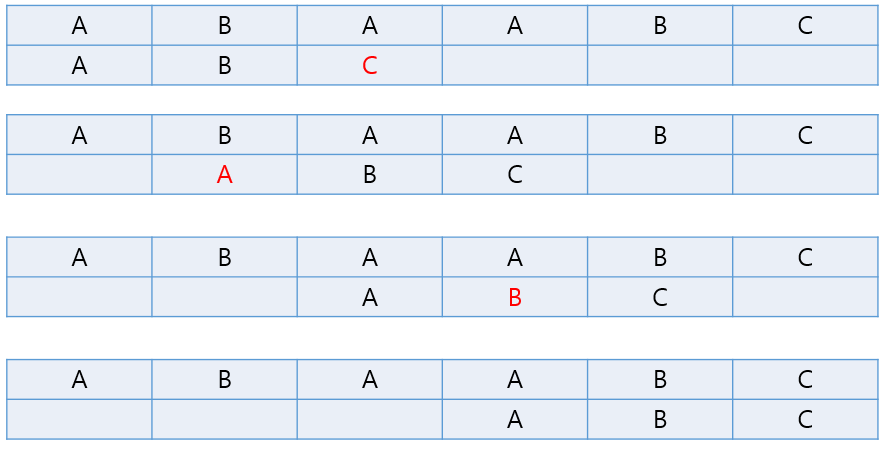
kmp 알고리즘을 활용하게 된다면, 해당 형식처럼 진행을 하게 됩니다.

kmp는 기존 문자열 매칭방식과 다르게 fail function이라는 실패 함수를 활용하게 됩니다.

"ABC"라는 단어의 몇번째 index까지 매칭되어 있는지에 대한 배열을 만들어 탐색할 때 사용하게 됩니다.
KMP는 간단하게 여기까지만 이야기하도록 하겠습니다.
Trie
trie는 트리형식의 문자열 탐색 알고리즘 입니다.
특정 단어들을 트리 형식으로 구성하여 찾고자 하는 단어가 들어왔을 때, 해당 단어가 존재하는지 여부를 확인할 수 있습니다.
{he, she, his, hers, ear}이라는 단어를 저장한다고 가정하도록 하겠습니다.
각 단어들을 char 형태로 나눈 트리 형식의 트라이 알고리즘 insert 순서를 보여드리겠습니다.
단어의 끝 문자의 경우 트리의 마지막 leaf노드로 bool 값을 true로 설정하여 단어의 끝을 나타냅니다.
{he, she, his, hers, ear}
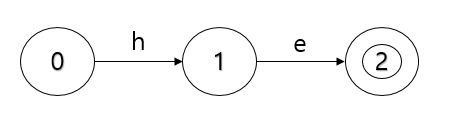
{he, she, his, hers, ear}

{he, she, his, hers, ear}
his라는 단어가 입력하게 될 때에는 root로부터 h라는 문자의 간선이 존재하여, 새로운 간선을 생성하지 않고 기존의 간선을 통하게 됩니다.
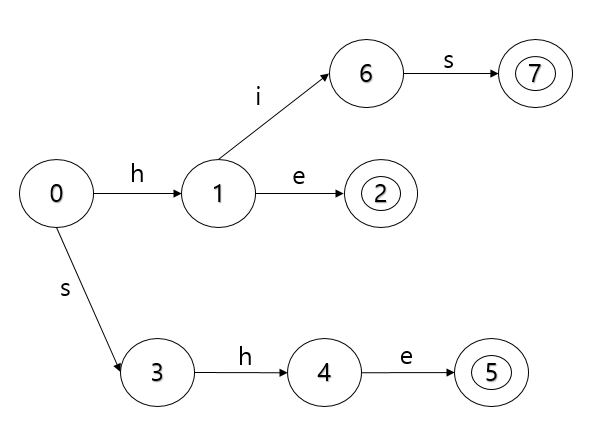
{he, she, his, hers, ear}
{he, she, his, hers, ear}

아호코라식
인제 kmp의 fail function과 trie를 활용하여 아호 코라식에 대해 설명드리겠습니다.
기존에 트라이는 찾고자 하는 단어가, 기존에 있던 단어들 중에 존재하는 지 확인하는 1:n 검색 알고리즘 이였습니다.
아호코라식은 여러 개의 단어들 중 매칭하고자 하는 단어의 부분 문자열인 단어가 존재하는 지 확인하는 알고리즘이라고 이해하시면 좋을거 같습니다.
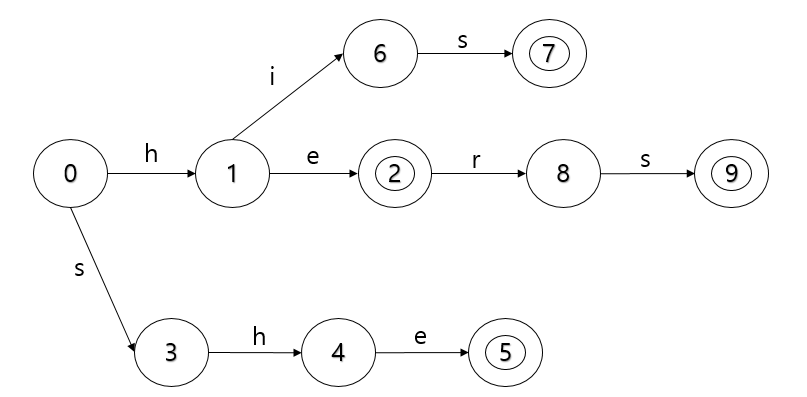
trie를 설명할 때 사용하였던 마지막 트리를 활용하도록 하겠습니다.
해당 트리에 fail function을 추가하게 되면 다음과 같은 트리가 만들어지게 됩니다. 빨간색 선은 fail function을 통하여 이동하는 노드를 가리키게 됩니다.

shr이라는 단어를 찾고자 할 때, s,h를 통해 이동하여 4번 노드에 도착하였으나, i로 갈 수 있는 노드가 없게 됩니다.
그러면 현재까지 있는 단어의 0번째 문자를 제외하여 root 노드로 부터 h라는 문자를 통해 갈 수 있는 1번 노드를 fail node로 가리키게 됩니다.
sheas이라는 단어로 진행을 하게 되면, s,h,e를 통해 5번 노드에 도착하였으나, a이라는 단어로 갈 수 있는 노드가 없습니다. 그래서 root 노드로 부터 h,e라는 문자를 통해 갈 수 있는 2번 노드를 fail node로 가리키게 됩니다.
이후 2번노드에서도 a로 갈 수 있는 노드가 없어 root 노드로 부터 e라는 단어를 통해 갈 수 있는 10번 노드를 fail node로 가리키게 됩니다.
해당 알고리즘을 활용하여 풀 수 있는 백준 문제로는 문자열 집합 판별이라는 문제가 있습니다.
'논문 리뷰' 카테고리의 다른 글
| Space/time trade-offs in hash coding with allowable errors (Bloom FIlter) (0) | 2024.11.20 |
|---|---|
| A Fast StringSearching Algorithm 리뷰 (0) | 2024.06.16 |


댓글